Abstract
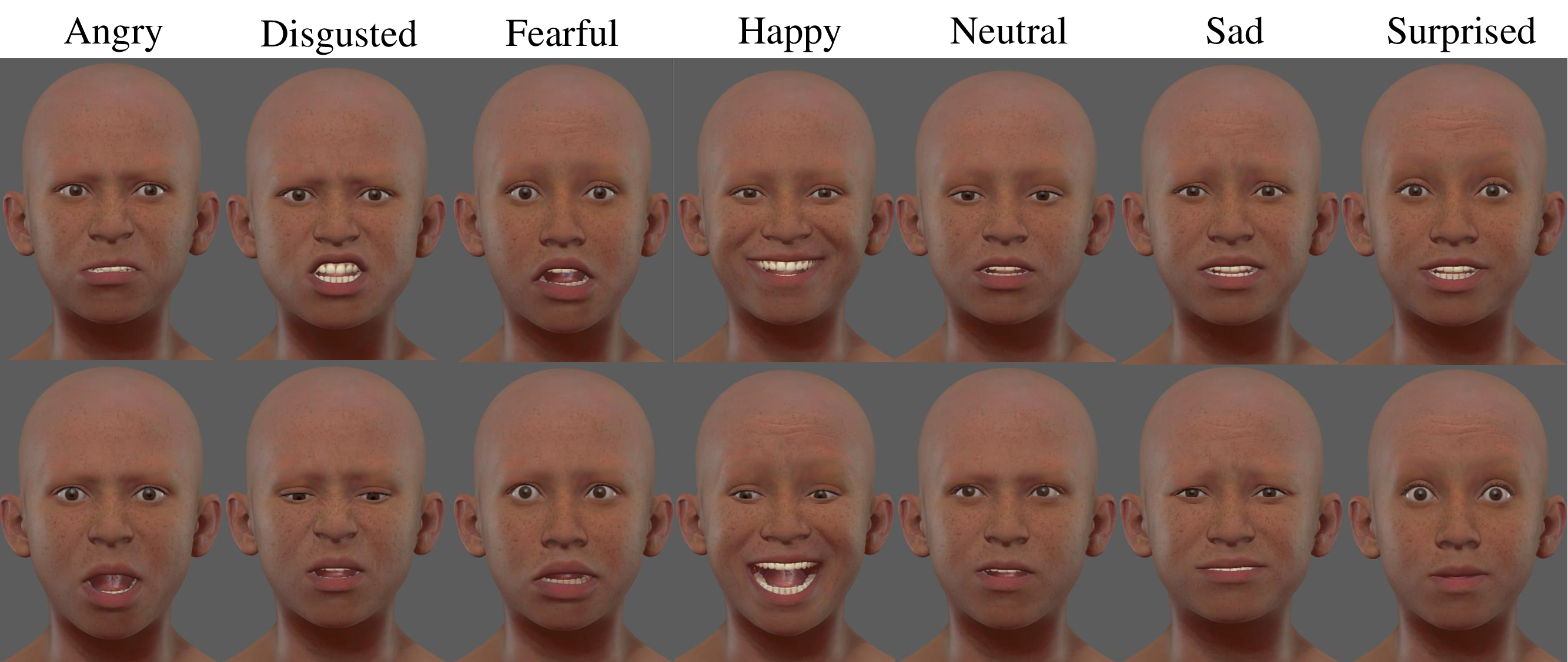
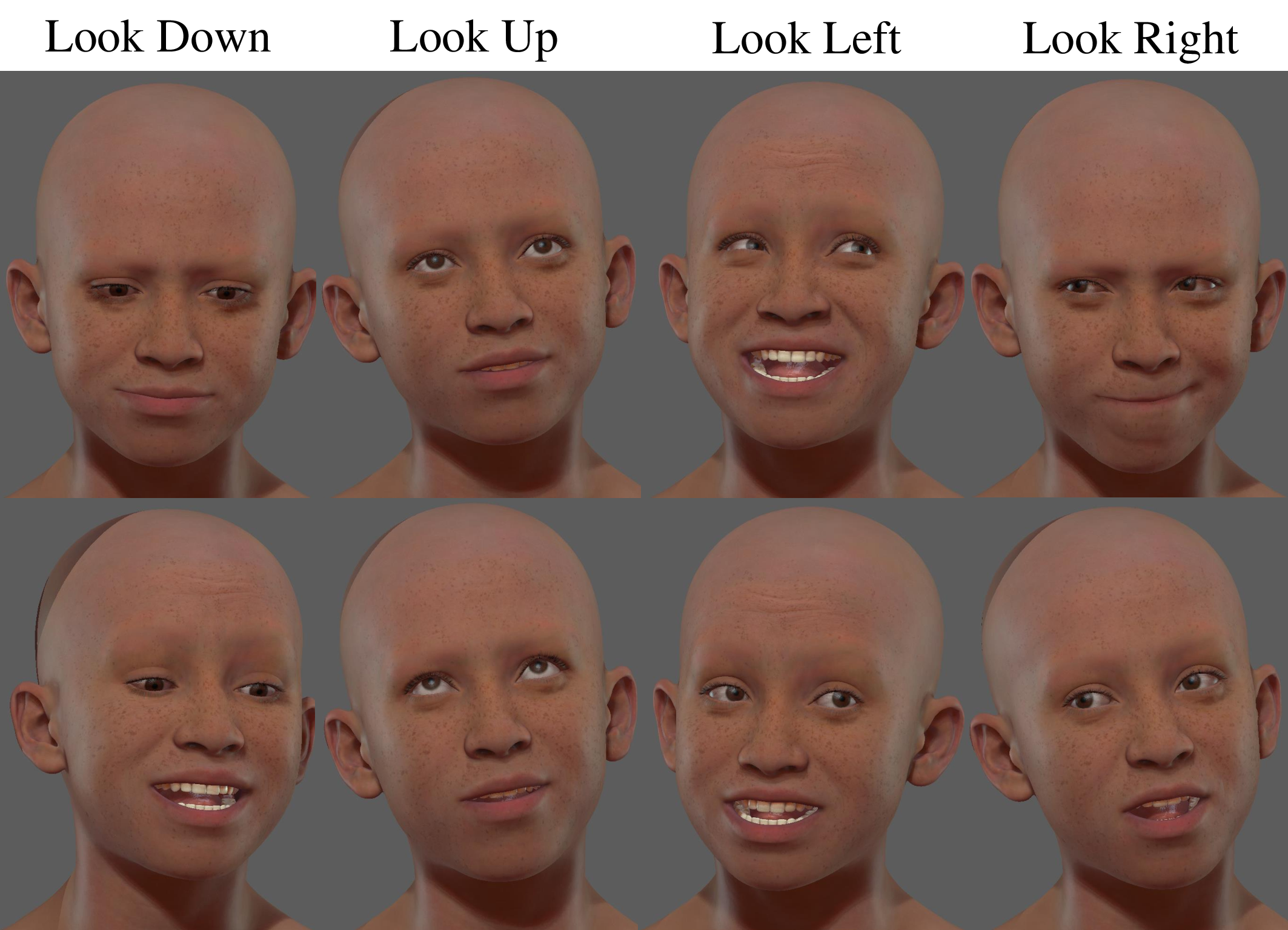

Audio-driven 3D facial animation is crucial for enhancing the metaverse's realism, immersion, and interactivity. While most existing methods focus on generating highly realistic and lively 2D talking head videos by leveraging extensive 2D video datasets these approaches work in pixel space and are not easily adaptable to 3D environments. We present VASA-Rig, which has achieved a significant advancement in the realism of lip-audio synchronization, facial dynamics, and head movements. In particular, we introduce a novel rig parameter-based emotional talking face dataset and propose the Latents2Rig model, which facilitates the transformation of 2D facial animations into 3D. Unlike mesh-based models, VASA-Rig outputs rig parameters, instantiated in this paper as 174 Metahuman rig parameters, making it more suitable for integration into industry-standard pipelines. Extensive experimental results demonstrate that our approach significantly outperforms existing state-of-the-art methods in terms of both realism and accuracy.
Key Contributions
- VASA-Rig Framework: Audio-driven 3D facial animation with vivid expression and natural gaze/head dynamics.
- New Emotional Dataset: Over 910,000 paired frames of 2D video and rig parameters for MetaHuman-centric training.
- Latents2Rig Model: A mapping network that adapts 2D facial animation latents to 3D rig control space.
- Industry Integration: Direct 174-parameter rig output that is lightweight and production-friendly.
How It Works: The VASA-Rig Pipeline
Our framework has three stages:
Large-Scale Emotional Dataset
To address the lack of public 3D talking-face data, we built a large-scale emotional dataset with over 4 hours (276+ minutes) of footage and around 910,000 frames of paired 2D video and rig parameters.
- Actor Capture: Professional artists mapped performances to MetaHuman rigs for high emotional fidelity.
- Livelink Capture: Live Link Face + iPhone capture with ARKit blendshapes for scalable collection.
- Diverse Render: Multiple characters (e.g., Ada, Emanuel, Emory, Tori) applied for rendering captured data for cross-identity generalization.
* For data privacy reasons, we are only showing 2D videos rendered using Metahuman.
Quantitative Evaluation
We evaluate VASA-Rig against state-of-the-art methods using SyncNet metrics (LSE-D and LSE-C) for lip-synchronization and FRD (Upper-Face Rig Deviation) for facial expression diversity. Our method achieves the lowest LSE-D and highest LSE-C, demonstrating superior lip-sync accuracy across both HDTF and RAVDESS datasets.
| Method | HDTF Dataset | RAVDESS Dataset | ||||
|---|---|---|---|---|---|---|
| LSE-D | LSE-C | FRD | LSE-D | LSE-C | FRD | |
| EmoTalk | 13.931 | 0.4545 | 0.0047 | 11.184 | 0.5200 | 0.0051 |
| EmoFace | 14.531 | 0.4505 | 0.0229 | 10.976 | 0.5028 | -0.0222 |
| Audio2Face | 14.428 | 0.4269 | 0.0352 | 11.194 | 0.5259 | 0.0275 |
| VASA-Rig (Ours) | 13.344 | 0.5191 | -0.0912 | 10.477 | 0.5722 | -0.0691 |
The table below illustrates the Standard Deviation (SD) of rig parameters across different facial regions. Compared to baseline methods which often produce "muted" or overly smoothed upper-face motions, VASA-Rig significantly enhances the expressive richness in the eyes, eyebrows, and nose areas, leading to more "live" and natural animations.
| Method | HDTF (Standard Deviation) | RAVDESS (Standard Deviation) | ||||
|---|---|---|---|---|---|---|
| Eyes | Eyebrows | Nose | Eyes | Eyebrows | Nose | |
| EmoTalk | 0.0345 | 0.0865 | 0.0089 | 0.0280 | 0.0649 | 0.0098 |
| EmoFace | 0.0234 | 0.0201 | 0.0088 | 0.0475 | 0.1193 | 0.0378 |
| Audio2Face | 0.0071 | 0.0145 | 0.0017 | 0.0080 | 0.0128 | 0.0030 |
| VASA-Rig (Ours) | 0.1174 | 0.2451 | 0.1037 | 0.0986 | 0.1681 | 0.0801 |
BibTeX
@article{pan2025vasa,
title={Vasa-rig: Audio-driven 3d facial animation with 'live' mood dynamics in virtual reality},
author={Pan, Ye and Liu, Chang and Xu, Sicheng and Tan, Shuai and Yang, Jiaolong},
journal={IEEE Transactions on Visualization and Computer Graphics},
year={2025},
publisher={IEEE}
}